
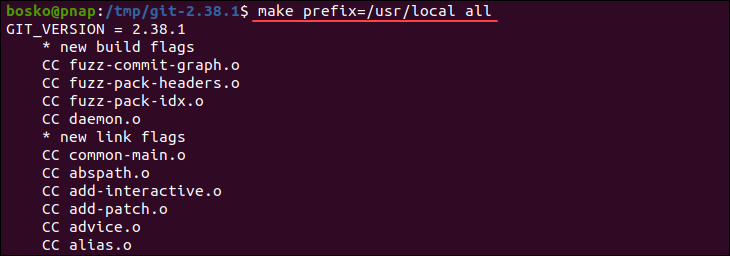
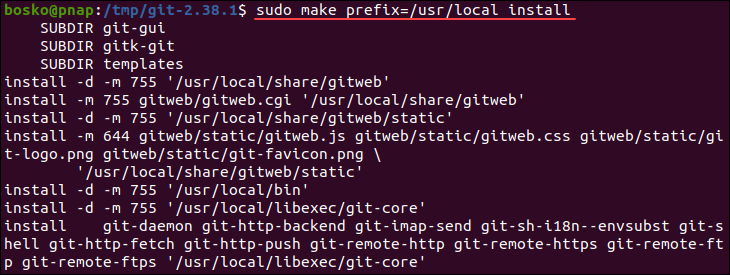

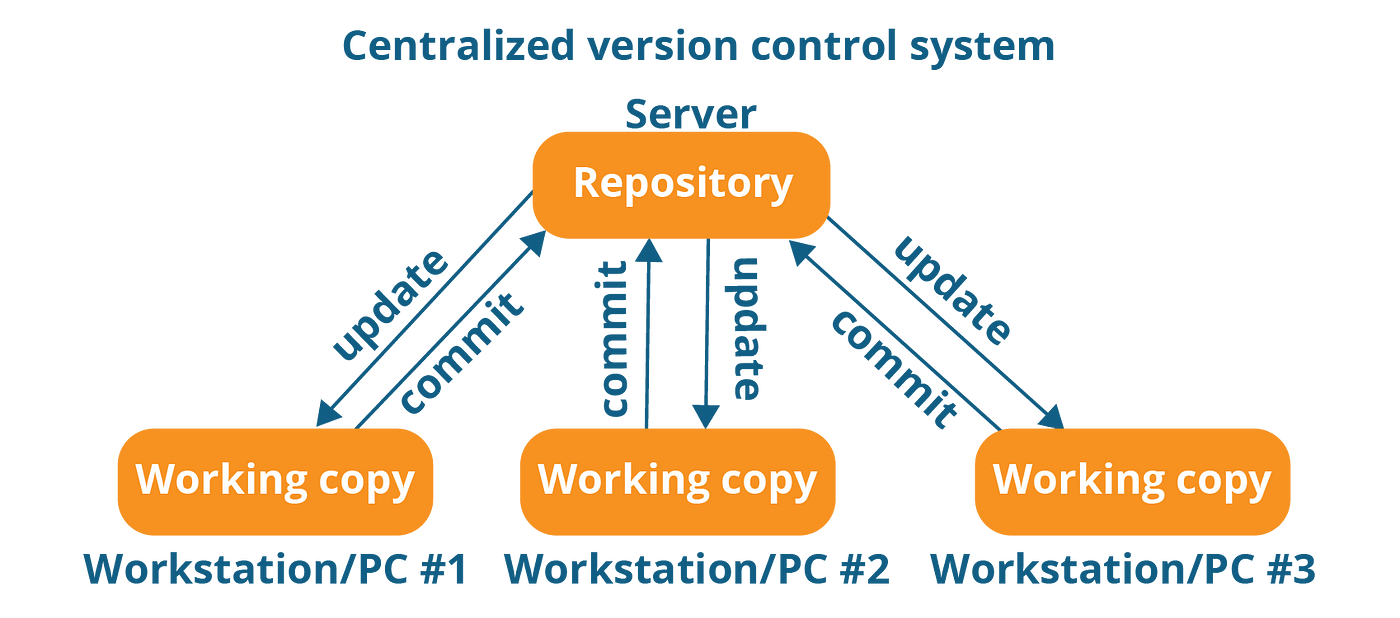
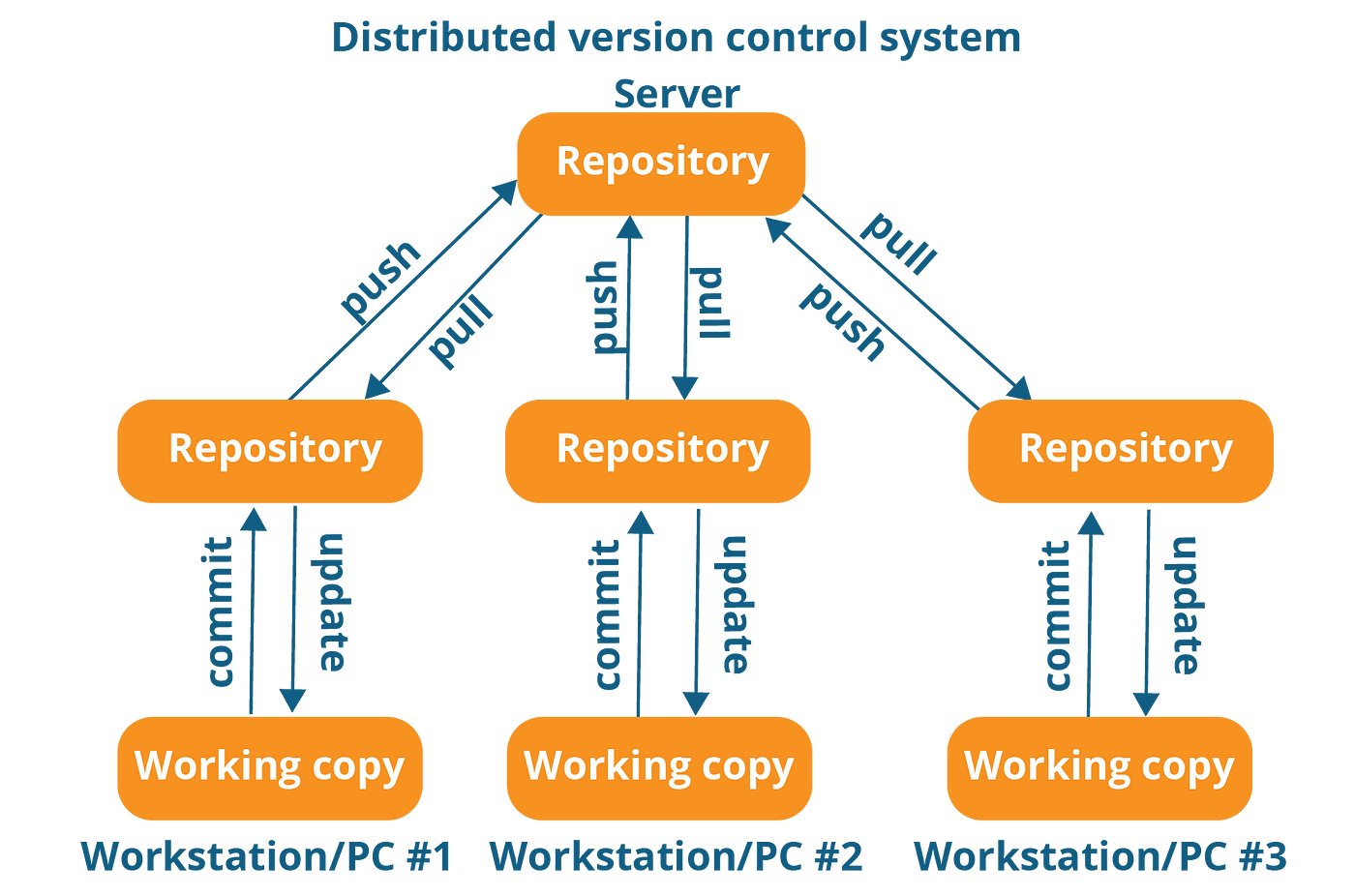


























































Git can be used to manage code quality by integrating with static code analysis tools like SonarQube or Codacy.
To integrate SonarQube with Git:
- Install the SonarScanner for your programming language and run it on your codebase:
$ sonar-scanner
- Configure the SonarQube server URL and access token in your Git repository:
$ git config sonar.host.url <sonarqube-url>
$ git config sonar.login <sonarqube-token>
- Add a Git hook to automatically run the SonarScanner on commit:
$ curl -sL https://raw.githubusercontent.com/SonarSource/sonar-scanning-examples/master/gitlab/.gitlab-ci.yml > .git/hooks/pre-commit
$ chmod +x .git/hooks/pre-commit
To integrate Codacy with Git:
- Sign up for a Codacy account and create a new project for your Git repository.
- Add a Codacy token to your Git repository:
$ git config --global codacy.apiToken <codacy-token>
- Add a Git hook to automatically run Codacy on commit:
$ curl -Ls --output codacy-coverage-reporter https://github.com/codacy/codacy-coverage-reporter/releases/download/4.1.0/codacy-coverage-reporter-linux
$ chmod +x codacy-coverage-reporter
$ curl -sL https://raw.githubusercontent.com/codacy/git-codacy-coverage/v4.1.0/git-codacy-coverage > .git/hooks/pre-commit
$ chmod +x .git/hooks/pre-commit
This allows you to automatically check the quality of your code with every commit and receive feedback on how to improve it.